Noviembre 20, 2023 |
Redis Ranking 👩🏻💻
Utilizamos las estructuras de datos de Redis para implementar un ranking
Utilizar Redis como base de datos para gestionar un ranking puede ser una buena idea (y de hecho lo es), y podemos verlo en este artículo que muestra un caso de uso de un ranking implementado con Redis, como también vamos a ver a continuación.
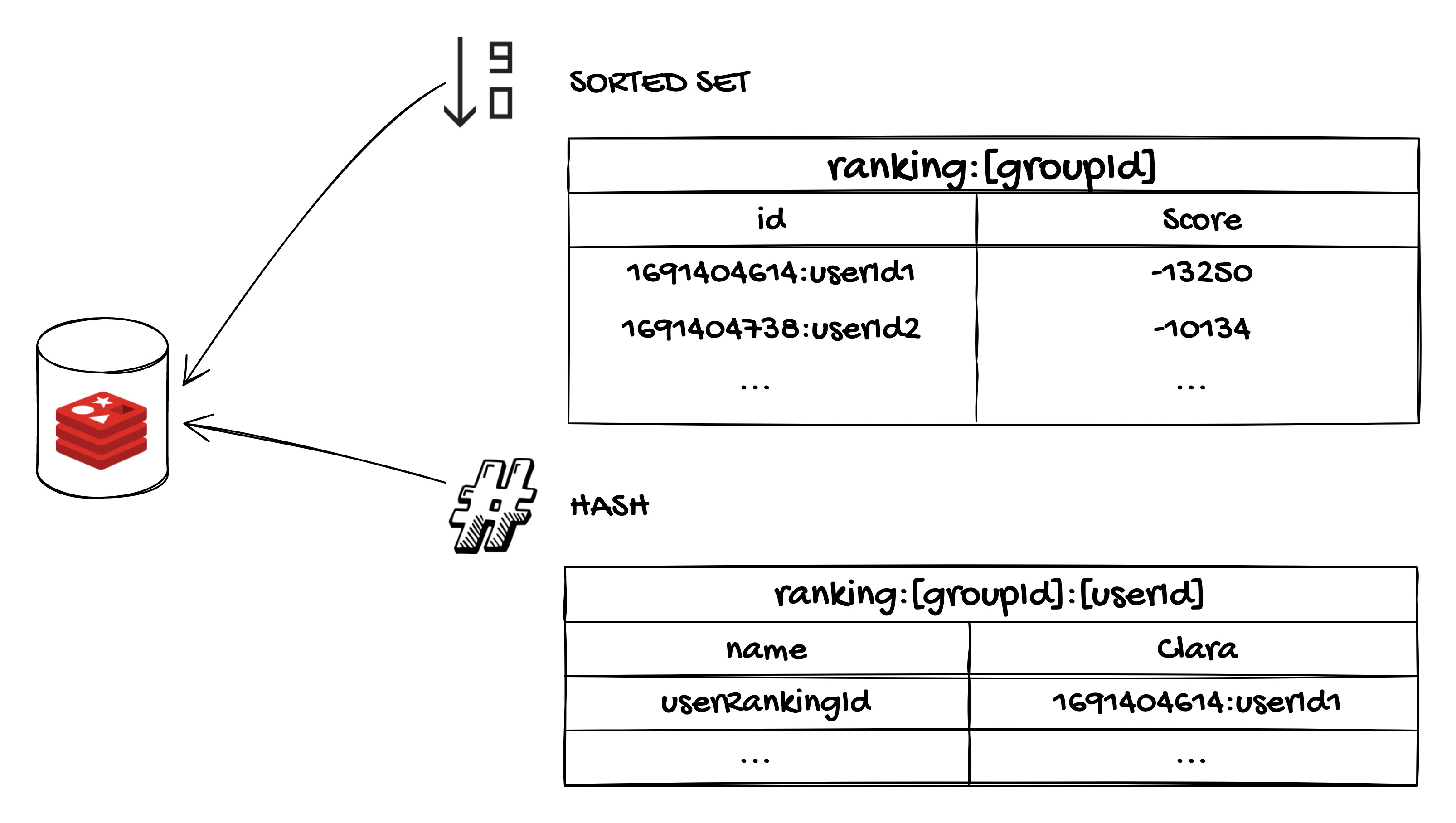
Concretamente, vamos a abordar una solución en la que poder crear varios rankings, asociados a distintos grupos de usuarios, ya que generalmente los usuarios de un sistema no suelen competir todos contra todos. Por cada grupo de usuarios para el que se quiera generar un ranking, se creará un sorted set con una clave identificativa del grupo, por ejemplo ranking:[groupId]. El score de los elementos del sorted set representará la puntuación de cada usuario respecto a la cual se ordena el ranking. El identificador de estos elementos estará compuesto por un identificador asociado al usuario y un valor desempatador para elementos con un mismo score. Así pues, este identificador tendrá el formato [timestamp]:[userId], siendo timestamp la fecha (como marca temporal de Unix en milisegundos) en que el usuario fue introducido en el ranking (por ejemplo, el momento en el que empieza a jugar un juego para el que se quiere obtener un ranking). Esto nos permitirá usar la ordenación lexicográfica de Redis para resolver los empates en puntuación automáticamente.
La puntuación se almacenará como un valor negativo en los sorted sets ya que Redis ordena los elementos de los sorted sets de menor a mayor puntuación, y si los almacenáramos con valores positivos y los rescatáramos en orden reverso para obtener en las primeras posiciones aquellos elementos con una mayor puntuación, Redis también resolvería en orden lexicográfico inverso los empates, resultando como ganador de un empate el jugador que entró más tarde al ranking en lugar del primero de ellos.
Para tener también almacenada la información asociada a cada usuario del sorted set usaremos hashes. Generaremos un hash por cada usuario con clave ranking:[groupId]:[userId]. Añadimos el identificador del grupo al que pertenece el usuario, y para el que estamos creando el ranking, con intención de facilitar operaciones en bulk sobre todos los usuarios de un grupo, como el borrado de los datos de todos los usuarios de un grupo.
Estos hashes contendrán al menos el nombre del usuario (name) y el identificador del usuario en el ranking (userRankingId, de formato [timestamp]:[userId], siendo timestamp la fecha en que el usuario entró en dicho ranking). Puede ser útil almacenar en el hash el nombre del usuario (así como otros atributos descriptivos del usuario) para recuperarlo y poder mostrarlo en una tabla en nuestra aplicación. En cuanto al campo userRankingId, al almacenarlo en el hash de cada usuario, podremos editar (o eliminar) fácilmente un usuario de un ranking. Si queremos sumar puntos a un determinado usuario en un ranking, conocemos su groupId y userId, rescatamos con ello el valor de su hash y utilizamos la propiedad userRankingId para identificar el elemento del sorted set al cual queremos incrementarle el score. A la hora de eliminar a un usuario de un ranking, eliminaríamos el hash del usuario y, seguidamente, podríamos eliminar el elemento correspondiente del sorted set haciendo uso de nuevo del userRankingId.
Para añadir un nuevo usuario al ranking utilizaríamos ZADD, añadiendo así un elemento al sorted set correspondiente. Lo podríamos hacer con la opción 'NX' para evitar sobreescribir elementos que ya estaban en el sorted set. Esto podría ser útil en caso de que tuviéramos varias instancias de un mismo servicio atendiendo a la necesidad de añadir un usuario nuevo a un ranking. Además, como se ha mencionado antes, el identificador del elemento que añadamos (itemId) deberá seguir la estructura [timestamp]:[userId].
async function addItemToSortedSet(sortedSetKey, itemId, itemScore = 0) {
return await redis.zadd(sortedSetKey, 'NX', itemScore, itemId);
}Para incrementar la puntuación de un elemento del sorted set usaríamos ZINCRBY indicando tanto la clave del sorted set como el identificador del elemento al que queremos aumentarle la puntuación.
async function incrementItemScore(sortedSetKey, itemId, points) {
await redis.zincrby(sortedSetKey, points, itemId);
}También podremos eliminar un usuario del ranking eliminando su elemento del sorted set con ZREM.
async function removeItemFromSortedSet(sortedSetKey, itemId) {
return await redis.zrem(sortedSetKey, itemId);
}Para saber la puntuación de un determinado usuario en un ranking podremos recurrir a ZSCORE.
async function getItemScore(sortedSetKey, itemId) {
return await redis.zscore(sortedSetKey, itemId);
}Además de la puntuación de un usuario, podremos conocer también la posición que ocupa en un determinado ranking haciendo uso de ZRANK.
async function getItemRank(sortedSetKey, itemId) {
return await redis.zrank(sortedSetKey, itemId);
}Si quisiéramos saber el número de usuarios que componen un determinado ranking podremos hacer uso de ZCOUNT.
async function getSortedSetCount(sortedSetKey) {
return await redis.zcount(sortedSetKey, '-inf', '+inf');
}Para obtener una lista con los elementos del sorted set ordenados adecuadamente según la puntuación (y la fecha de entrada al ranking en caso de empate) usaríamos ZRANGEBYSCORE indicando que queremos recuperar todos los elementos con score entre '-inf' y '+inf'.
async function rangeByScore(key, limit) {
return await redis.zrangebyscore(key, '-inf', '+inf', 'LIMIT', 0, limit);
}Podríamos utilizar de forma equivalente ZRANGE con la opción 'WITHSCORES' para obtener las puntuaciones de los elementos además de sus identificadores, pero en este caso los límites inferior y superior no se referirían a valores mínimo y máximo de score sino a las posiciones que ocupen los elementos en el sorted set. Esto último puede ser útil para implementar un sistema de paginado a la hora de rescatar los elementos del sorted set.
async function rangeByScorePaginated(sortedSetKey, { page = 1, limit = 10 } = {}) {
const from = (page - 1) * limit;
const to = from + limit - 1;
let rangedSortedSet = await redis.zrange(sortedSetKey, from, to, 'WITHSCORES');
// zrevrange returns an array with format [id, score, id, score, ...]
// This way we will turn it into an array with format [[id, score, rank], [id, score, rank], ...]
let itemRank = from + 1;
rangedSortedSet = rangedSortedSet
.map((itemId, index, array) => {
if (index % 2 === 0) {
const itemScore = array[index + 1];
return [itemId, parseInt(itemScore), itemRank++];
}
return null;
})
.filter((def) => def);
return rangedSortedSet;
}A partir de la versión 6.2.0 de Redis, ZRANGE puede sustituir totalmente a los comandos ZREVRANGE, ZRANGEBYSCORE, ZREVRANGEBYSCORE, ZRANGEBYLEX y ZREVRANGEBYLEX porque permite determinar valores límite inferior y superior distintos de la posición que ocupen en el sorted set los elementos, pudiendo hacer estos referencia al score (utilizando la opción 'BYSCORE') o al léxico del identificador (utilizando la opción 'BYLEX'), por ejemplo.
En cuanto al hash que almacenamos con datos de cada usuario, podremos crearlo con HMSET, recuperar su información con HGETALL o con HGET para recuperar solo el valor de un atributo, modificar el hash con HMSET o un atributo concreto con HSET (o HSETNX si queremos añadir nuevos atributos pero evitar sobreescribir atributos existentes), y eliminar algún atributo del hash con HDEL. Para eliminar el hash, como para eliminar el sorted set o cualquier otra estructura de datos de redis, eliminaríamos su clave con DEL.
async function getHashData(hashKey) {
return await redis.hgetall(hashKey);
}async function getHashField(hashKey, field) {
return await redis.hget(hashKey, field);
}async function createHash(hashKey, data) {
const hashAlreadyExists = !!(await redis.exists(hashKey));
if (!hashAlreadyExists) {
await redis.hmset(hashKey, data);
}
return await redis.hgetall(hashKey);
}async function updateHash(hashKey, newData) {
return await redis.hmset(hashKey, newData);
}async function updateHashField(hashKey, field, value) {
return await redis.hset(hashKey, field, value);
}async function addHashField(hashKey, field, value) {
return await redis.hsetnx(hashKey, field, value);
}async function deleteFieldsFromHash(hashKey, fields) {
await redis.hdel(hashKey, fields);
}async function deleteHash(hashKey) {
await redis.del(hashKey);
}Para concluir, hemos visto cómo podemos recurrir a Redis para implementar un ranking con sus estructuras de datos y beneficiarnos así de una lectura y escritura rápida en memoria para una información que va a estar en constante cambio. Sin embargo, al ser una base de datos en la que la información se almacena en memoria, si el servicio que gestiona dicha base de datos cayera, caerían con él todos los datos almacenados. Por eso, para evitar que esta desventaja nos limite y nos impida usar Redis para este caso de uso (o cualquier otro en el que la pérdida de los datos sea algo crítico), deberemos optar siempre por mantener backups de nuestros datos.
“Sorted Sets (ZSETs) within Redis are a built-in data structure that makes leaderboards simple to create and manipulate.”
Redis Techies